

Jezikovni viri starejše slovenščine IMP
Na tej strani najdete spletno dostopne jezikovne vire za starejšo slovenščino, ki vsebujejo dela do leta 1918. Večina jih je iz 19. stoletja, v manjši meri pa najdemo tudi starejše knjige, vse do vzorca Dalmatinove Biblije iz leta 1584. Če želite brati knjige, si poglejte digitalno knjižnico s preko 650 enotami oz. 45.000 stranmi. Za takratnimi besedami pobrskajte v besedišču zastarelih besed, za natančnejše preučevanje zgodovinskega jezika pa služi konkordančnik, ki vsebuje dva korpusa označenih besedil iz tega časa. Korpusa in besedišče služijo tudi za razvoj jezikovnih tehnologij, ki bi omogočale lažji dostop do naše pisne kulturne dediščine.
Namen, nastanek in zgradba virov starejše slovenščine IMP so bolj podrobno opisani v bibliografiji projekta. Viri IMP so bili viri meseca maja 2015 na Portalu jezikovnih virov.
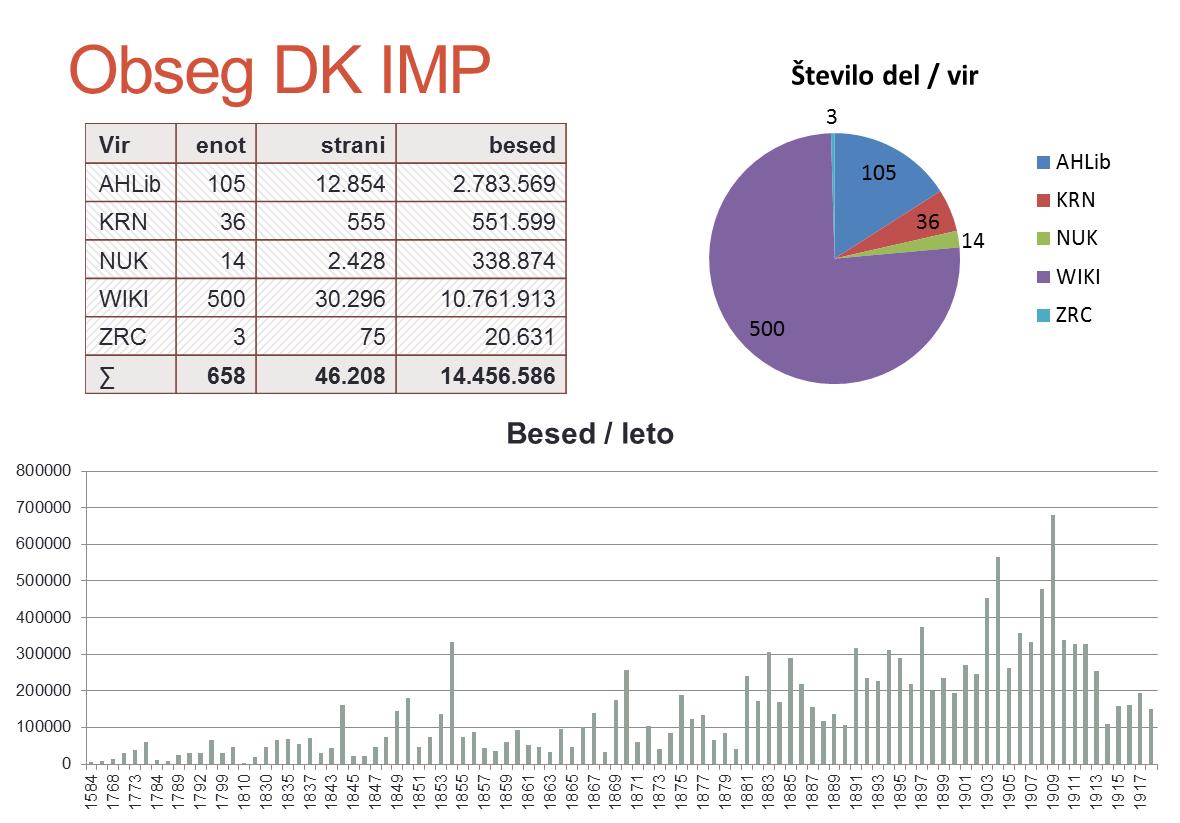
Digitalna knjižnica
Digitalna knjižnica vsebuje preko 600 knjig, izdanih od konca 16. stoletja do 1918, z večino iz druge polovica 19. stoletja. Poleg knjig so v knjižnico vključene tudi izdaje časopisa "Kmetijske in rokodelske novice" in posamezni rokopisi.
Vsaka enota vsebuje kolofon, faksimile in čistopis. Za branje so dostopne preko kazal, ki so urejena po:
- avtorju (enote z neznanim avtorjem so na začetku seznama)
- naslovu
- letu izdaje, tudi s prikazom naslovnic
- signaturi.
Knjižnica je dostopna tudi kot avtomatsko označen korpus IMP prek konkordančnika noSketch Engine.
V zbirki IMP so zbrana dela iz več virov, ki imajo naslednje signature:
- WIKI: projekt Wikivir ‘Slovenska leposlovna klasika’, ki vsebuje leposlovne knjige, podlistke in rokopise slovenskih avtorjev
- FPG: zbirka AHLib, z v slovenščino prevedenimi knjigami nemških avtorjev iz obdobja 1848–1918
- NUK: starejše knjige, ki jih je pripravila NUK v okviru projekta IMPACT
- KRN: izbrani izvodi časopisa "Kmetijske in rokodelske novice", NUK/IMPACT
- ZRC: vzorci treh verskih knjig (od tega dve najstarejši v knjižnici), ki jih je pripravil ZRC SAZU
Korpusi
Referenčni korpus starejše slovenščine goo300k vsebuje 1.100 strani besedila (okoli 300.000 pojavnic), ki so bile vzorčene iz zbirke besedil IMP, besedilo in oznake pa so bile ročno preverjene. Korpus je dokumentiran v svojem kolofonu TEI. Večji korpus IMP je narejen iz celotne zbirke IMP, označen pa je avtomatsko, zato je delež napak v njem dosti večji. Korpusa sta dostopna za pregledovanje in analizo prek CLARIN.SI instalacije spletnega konkordančnika (IMP, goo300k). Dostopna sta za prevzem z repozitorija CLARIN.SI (IMP, goo300k), kjer so na voljo tudi n-grami korpusa IMP.
V korpusih je vsaka beseda (npr. "lubesni") označena z naslednjimi podatki:
- posodobljena oblika, npr. "ljubezni";
- lema ali osnovna oblika, npr. "ljubezen"
- oblikoskladenjska oznaka, npr. "Som" za "samostalnik vrsta=občno_ime spol=moški" (oznake so definirane v Oblikoskladenjskih specifikacijah IMP).
Besedišče
Na podlagi ročno označenega korpusa (4 mio. pojavnic) smo izdelali besedišče oz. leksikon. Za geselsko iztočnico služi sodobna lema s pripisanimi informacijami, kot so besedna vrsta in najbližje sodobne ustreznice za zastarele besede. Iztočnici sledijo posodobljene besedne oblike in njihove korpusno atestirane izvirne besedne oblike. Gesla so, kjer je to smiselno, povezana na konkordančnik s korpusoma goo300k in IMP in na spletni SSKJ in Pleteršnika, primeri uporabe iz korpusa pa z digitalno knjižnico. Kot primer si lahko pogledate geslo čimž.
Besedišče je dokumentirano v svojem kolofonu TEI in je dostopno za pregledovanje na spletu. Ker je celotno besedišče obsežno in vsebuje gesla, ki večini uporabnikom ne bodo zanimiva, smo ga pripravili v več različicah:
- malo besedišče
vsebuje samo zastarele besede, pri čemer je vsaki pripisana sodobna ustreznica oz. razlaga; - srednje veliko besedišče
vsebuje gesla, ki imajo vsaj eno besedno obliko, ki so jo nekoč pisali drugače, kot jo pišemo danes; - veliko besedišče
vsebuje vsa gesla razen nezanimivih, kot so imena, cifre, tiskarski škrati itd. - celotno besedišče
vsebuje čisto vsa gesla besednih pojavnic iz ročno označenega korpusa.
Besedje starejše slovenščine imp25k 1.1 je dostopno za prezvem prek repozitorija CLARIN.SI.
Prevzem
Viri IMP so dostopni za prevzem z repozotorija CLARIN.SI:
- Referenčni korpus starejše slovenščine goo300k 1.2:
hdl.handle.net/11356/1025 - Digitalna knjižnica in korpus starejše slovenščine IMP 1.1:
hdl.handle.net/11356/1031 - Besedni n-grami korpusa IMP 2.0:
hdl.handle.net/11356/1194 - Besedje starejše slovenščine imp25k 1.1:
hdl.handle.net/11356/1032
Če boste uporabili katerega od teh virov, jih citirate kot je navedeno na njihovih straneh v repozitoriju CLARIN.SI oz. sledečo referenčno objavo:
Tomaž Erjavec. 2015. The IMP historical Slovene language resources. Language resources and evaluation 49/3, 753-775. doi: 10.1007/s10579-015-9294-7.
Zapis virov je skladen s shemo XML, ki temelji na smernicah TEI P5. Besedišče in označeni korpus sta na voljo tudi v tabelaričnem formatu, ki je manjši in preprostejši za uporabo, vendar pa ne vsebuje vseh informacij iz izvornega XML.
Več o namenu, izgradnji in zgradbi virov IMP lahko preberete v bibliografiji projekta.
Zahvala
Pri izdelavi jezikovnih virov IMP so sodelovali Kozma Ahačič, Tina Benčina, Katja Cingerle, Metod Čepar, Darja Fišer, Miran Hladnik, Alenka Jelovšek, Urška Kamenšek, Alenka Kavčič Čolić, Domen Kermc, Maša Kodrič, Simon Krek, Nina Mikulin, Matija Ogrin, Daša Pokorn, Erich Prunč, Zala Šmid, Ines Vodopivec in Maja Žorga Dulmin.
Delo sta omogočila projekt EU IP IMPACT “Improving Access to Text” in nagrada Google “Developing Language Models of Historical Slovene”.
Bibliografija
Tomaž Erjavec. 2015. The IMP historical Slovene language resources. Language resources and evaluation 49/3, 753-775. doi: 10.1007/s10579-015-9294-7. [PDF]
Yves Scherrer, Tomaž Erjavec. 2015. Modernising historical Slovene words. Natural Language Engineering. doi: 10.1017/S1351324915000236.
Tomaž Erjavec, Darja Fišer. 2014. Recepcija virov starejše slovenščine IMP. V: ŽBOGAR, Alenka (ur.). Recepcija slovenske književnosti, (Obdobja, ISSN 1408-211X, Simpozij, = Symposium, 33). str. 119-127.
Tomaž Erjavec. 2014. The IMP project: developing resources for historical Slovene. Predavanje na prvi delavnici COST akcije ENeL. 29. september, 2014, Bled [prosojnice].
Tomaž Erjavec. 2013. Jezikoslovni viri starejšega slovenskega jezika IMP: digitalna knjižnica, korpus, slovar. Lingvistični krožek, 25. marca 2013. [prosojnice].
Tomaž Erjavec. 2013. Posodabljanje starejše slovenščine. Uporabna informatika, 21/4, str. 186-195.
Yves Scherrer, Tomaž Erjavec. 2013. Modernizing historical Slovene words with character-based SMT. 4th Workshop on Balto-Slavic Natural Language Processing, August 8-9, Sofia, Bulgaria. ACL 2013. str. 58-62.
Tomaž Erjavec, Ines Jerele, Maša Kodrič. 2011. Izdelava korpusa starejših slovenskih besedil v okviru projekta IMPACT. V: KRANJC, Simona (ur.). Meddisciplinarnost v slovenistiki, (Obdobja, Simpozij, = Symposium, 30). Ljubljana: Znanstvena založba Filozofske fakultete, 2011, 41-47
Tomaž Erjavec. Slovenska prevodna književnost 1848-1918 : digitalna knjižnica in korpus AHLib. V: KRANJC, Simona (ur.). Meddisciplinarnost v slovenistiki, (Obdobja, Simpozij, = Symposium, 30). Ljubljana: Znanstvena založba Filozofske fakultete, 2011, str. 33-40.
Tomaž Erjavec. 2012. The goo300k corpus of historical Slovene. V zborniku Eighth International Conference on Language Resources and Evaluation (LREC'12), Istanbul.
Tom Kenter, Tomaž Erjavec, Maja Žorga Dulmin, Darja Fišer. 2012. Lexicon construction and corpus annotation of historical language with the CoBaLT editor. V zborniku EACL Workshop on Language Technology for Cultural Heritage, Social Sciences, and Humanities, Avignon, France, April. Association for Computational Linguistics.
Ines Jerele, Tomaž Erjavec, Daša Pokorn, Alenka Kavčič-Čolić. 2012. Optical Character Recognition of Historical Texts: End-User Focused Research for Slovenian Books and Newspapers from the 18th and 19th Century. Review of the National Center for Digitization 21/2012, Faculty of Mathematics, Belgrade.
Tomaž Erjavec. Automatic linguistic annotation of historical language: ToTrTaLe and XIX century Slovene. V zborniku 5th ACL-HLT Workshop on Language Technology for Cultural Heritage, Social Sciences, and Humanities, 2011, Portland.
Tomaž Erjavec, Christoph Ringlstetter, Maja Žorga, Annette Gotscharek. A lexicon for processing archaic language: the case of XIXth century Slovene. V zborniku WoLeR: ESSLLI Workshop on Lexical Resources, 2011, Ljubljana.
Tomaž Erjavec, Christoph Ringlstetter, Maja Žorga, Annette Gotscharek. Towards a Lexicon of XIXth Century Slovene. V zborniku Seventh Language Technologies Conference Ljubljana, 2010.
Povezave
- AHLib: digitalna knjižnica in korpus starejših slovenskih knjig
- JOS: jezikoslovni viri za sodobno sloveščino
- Text Encoding Initiative in TEI P5