Our decision to use FOIDL for learning Slovene declensions was based on its properties listed in the previous Section and its success on the English past tense learning problem. The training sets sizes were chosen with regard to FOIDLs computational efficiency limits, i.e., not to exceed 500 examples. FOIDL was run three times, once for each target concepts, which in turn correspond to the three genders of Slovene nouns in their singular genitive form (nxfsg, nxmsg, and nxnsg).
The sizes of the entire datasets were 2755, 2893 and 1323 facts, for the female, male, and neuter gender, respectively. respectively. For training, one sixth of the nxfsg and nxmsg sets and one third of the nxnsg set were randomly chosen. The remainder of the data were used to test the performance of the rules induced by FOIDL. The rules reported on in this section were generated in this fashion.
We also performed a series of five FOIDL runs for each gender, where the training sets were half the size of the above, comprising between 220 and 250 examples. In each of the five runs, the training examples were chosen randomly (a different choice for each of the five runs). The average and standard deviation of the accuracies (over the five runs) on the testing examples were measured.
The general set-up for the experiments was exactly as for the orthographic past
tense learning experiment of Mooney and Califf, i.e., the training data
was encoded as PROLOG facts of the form:![]()
nxfsg([a,b,e,c,e,d,a],[a,b,e,c,e,d,e]). nxfsg([a,g,o,n,i,j,a],[a,g,o,n,i,j,e]). nxfsg([b,o,l,e,cx,i,n,a],[b,o,l,e,cx,i,n,e]). ...
The first argument of each target predicates (the lemma) is an input argument and the second is an output argument. The predicate split is used as background knowledge. Constant prefixes and suffixes are allowed in the rules.
The programs generated for the three concepts show varying degrees of success in capturing the relevant morphological generalizations. First, it should be noted that due to the random sampling of the dataset some low-frequency alternations were not included in the training set. The rules to generate such forms were obviously not discovered by FOIDL. Second, as has been already mentioned, FOIDL works only with the orthographic representation of the words, which does not contain enough information to predict the correct rule for generating the singular genitive form in all cases.
In brief, the rules induced from the larger training sets achieve accuracy on unseen (testing) examples of 99.1% for feminine, 95.9% for neuter, and 86.4% for the masculine gender. The average accuracies on unseen examples for the five runs with smaller training sets are 99.3 (0.1)%, 94.4 (3.3)%, and 85.0 (2.4)%, respectively (the numbers in brackets are the standard deviations). These accuracies are as would be expected from the number of 'rules' as discussed in Section 2, i.e., 10 for the feminine, 11 for neuter, and 24 for masculine. We examine first the simplest case of the feminine gender, and then the most complicated one of the masculine gender.

Table 3: FOIDL rules for feminine
The feminine case is the simplest of the three, and the rules that FOIDL generates to cover it are given in Table 3.
It can be seen that FOIDL correctly induced the three most frequent rules of Table 2. As the base form of a noun for these three cases gives an unambiguous cue for to the rule to be applied, and as these three cases cover the vast majority of feminine nouns, the accuracy of 99.1% comes as no surprise. the errors are all due to the rare alternations and idiosyncratic nouns not covered in the training set.

Table 4: FOIDL rules for masculine: exceptions
However, it should be noted that the first rule redundantly tests whether the suffix of the base form is -v, as it then performs a specialization of this test, namely whether the suffix is -ev. This type of redundancy occurs in the other two concepts as well: it is due to the greedy search of FOIDL\ and can be removed by post-processing similar to the one used in later versions of FOIL [5].
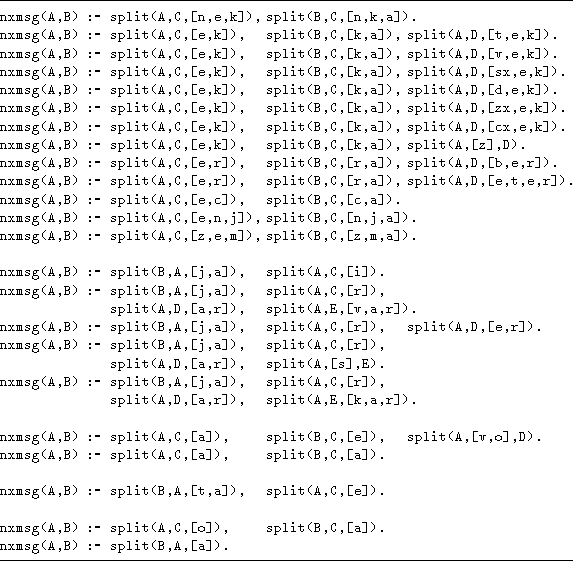
Table 5: FOIDL rules for masculine: generalisations
This is the most varied case, as 24 rules are needed to cover the complete data set. These cover four different paradigm classes, as well as numerous alternations and idiosyncratic nouns. A number of cases (30) were treated by FOIDL as exceptions, and some examples are given in Table 4. The first two cases are, respectively, an example of the second and third masculine paradigms. Here FOIDL is correct in postulating them as exceptions, as insufficient information is available in the base form to correctly predict the genitive. The next three cases are examples of an ending alternation which affects some short nouns; instead of the usual -a ending, the -u ending appears in the genitive case. As there is no rule that would predict which nouns fall in this class, FOIDL is correct in treating them as exceptions. The same holds for the next group, which encompasses the rare and unpredictable case of -o- and -e- elision. The last two groups are, however, different. Both contain examples of a productive alternation of (-e- elision and stem lengthening with -j-), which are, furthermore also encompassed in the generalization rules that follow.
The generalization rules are given in Table 5. For
illustrative purposes they have been reordered to make natural groups,
taking care, however, that the procedural semantics of the program
remains the same. The first group tries to model the -e-
elision alternation, by listing all the possible end-strings of the
base forms where it occurs. The second group models stem lengthening
by -j-. The third group covers masculine nouns ending in
-a, i.e., belonging to the second masculine
paradigm.![]() The penultimate group covers a common
alternation whereby nouns ending in -e in the base form
lengthen their stem with -t- with non-null endings. Finally,
the last group takes nouns ending in -o or -0 and
appends to them the canonical first declension ending -a.
The penultimate group covers a common
alternation whereby nouns ending in -e in the base form
lengthen their stem with -t- with non-null endings. Finally,
the last group takes nouns ending in -o or -0 and
appends to them the canonical first declension ending -a.
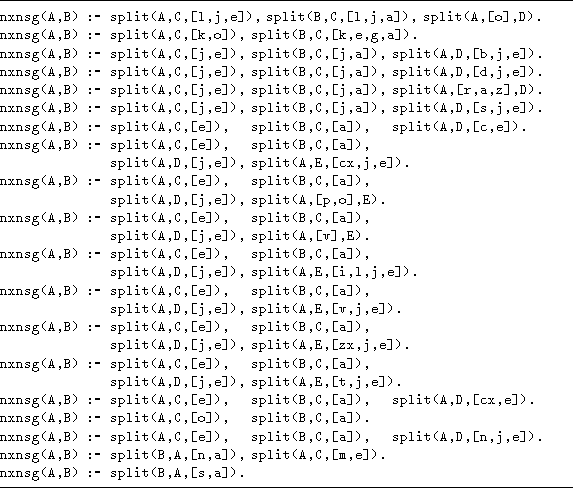
Table 6: FOIDL rules for neuter: generalisations
The neuter case needs 11 rules to generate all the genitive forms from the data set. From the 441 training examples, FOIDL generates a decision list with 18 clauses and 5 exceptions. The accuracy of this decision list on the remaining 882 cases is 95.9%.
The clause nxnsg(A,B) :- split(A,C,[o]), split(B,C,[a]) (fourth from the bottom) corresponds to the second most common rule -o/+a represented by 315 instances in the complete dataset. The bottom clause corresponds to the rule -/+sa, represented by 2 instances, the next clause corresponds to the rule -/+na, represented by 9 instances, and the second clause from the top to the rule -/+ga, represented by 2 instances. The remaining clauses all try to approximate the rule -e/+a, represented by 969 instances in the entire dataset.