V Skupini za govor in jezik Odseka za inteligentne sisteme na IJS sodelujemo v evropskem projektu MULTEXT-East (Multilingual Text Tools and Corpora for Central and Eastern European Languages, [EIPV96]). Projekt je podaljšek evropskega projekta MULTEXT, v katerem so sodelovale inštitucije iz šestih držav članic Evropske unije. MULTEXT-East je dvoletni projekt, ki se je začel maja 1996, v njem pa sodeluje poleg koordinatorja iz Aix-en-Provance in pridruženega partnerja iz Pise še šest skupin iz držav srednje in vzhodne Evrope, in sicer Bolgarije, Češke, Estonije, Madžarske, Romunije in Slovenije.
Eden od ciljev MULTEXT-East je proizvesti standardiziran večjezikovni korpus, ki vsebuje približno dva milijona besed, sestavljen pa je iz naslednjih delov:
Celoten korpus je označen po priporočilu CES; poleg bibliografskih oznake vsebujejo strukturne informacije (odstavki, članki, naslovi, premi govor itd.) ter določene ``posebne besede'', npr. lastna imena in okrajšave. Kot primer, kako takšne označbe izgledajo, sta v sliki 3 podana dva fragmenta iz slovenskega in češkega prevoda 1984.

Slika: Slovenska in češka fragmenta iz ``1984''
Del korpusa bo tudi dodatno označen: vsi prevodi 1984 bodo stavčno poravnani z originalom, medtem ko bo del korpusa označen še z oblikoslovnimi oznakami.
Oblikoslovno označevanje je najzahtevnejši del nadgradnje osnovnega (CES-3) korpusa. Da lahko (pol)avtomatsko označimo besedne oblike v korpusu z njihovimi oblikoslovnimi oznakami, so potrebni naslednji koraki: definirati je potrebno oblikoslovne kategorije, nato izdelati slovar, ki za vsako besedno obliko določi njene možne oznake, sestavljene iz oblikoslovnih kategorij, in z njegovo pomočjo polavtomatsko označiti besedila.
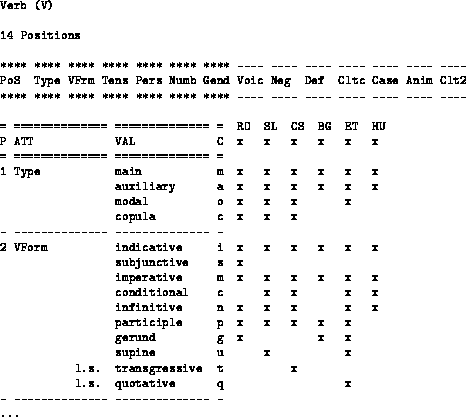
Slika: Začetek MULTEXT-East tabele za glagol
Ker je projekt večjezikovni, je potrebno oblikoslovne oznake definirati v skupnem formatu za šest jezikov. Kot primer iz MULTEXT-East 'slovnice' je v sliki 4 podan začetek tabele za glagole: ta določa, da glagolsko besedo opisuje 14 lastnosti. Najprej je podana besedna vrsta (tj. glagol, V), v tabeli pa vidimo definicijo prvih dveh lastnosti glagola; za vsako lastnost je podano ime ter nabor njenih vrednosti. Imenu vrednosti sledi enočrkovna koda le-te ter določitev, katere jezike opisuje. Tako npr. slovenščina loči glagolske oblike povednika, velelnika, pogojnika, nedoločnika, deležnika ter namenilnika.
Že iz zgornjega bo jasno, da določitve MULTEXT-East za oblikoslovje mestoma odstopajo od tradicionalnih kategorij v slovenskih slovnicah; tako so npr. glagolska deležja in glagolniki razvrščeni med prislove in samostalnike. Takšna odstopanja so v veliki meri posledica usklajevanja zapisov šestih med seboj zelo različnih jezikov, posredno pa dvanajstih, saj so tabele usklajene tudi z jeziki MULTEXT.
Predstavljeni format ima to prednost, da je neko oblikoslovno oznako mogoče zapisati v kompaktnem, obenem pa še vedno berljivem zapisu: tako npr. niz Vmip3s določa vrednosti Verb main indicative present third singular oz. povednik glavnega glagola v tretji osebi ednine.
Naslednji korak je izdelava slovarjev, ki v MULTEXT-East vsebujejo 15.000 gesel za vsakega od šestih jezikov projekta. Ti slovarji poleg samih korpusov predstavljajo tudi pomemben vir jezikovnih podatkov.

Slika 5: Fragment MULTEXT-East slovarja
Slovarji imajo preprosto, pa vendar precej informativno strukturo: vsak vnos je sestavljen iz besedne oblike, njenega gesla ter njenih oblikoslovnih značilnosti. Primer vnosov za besedno obliko berači je podan v sliki 5.
S slovarjem je nato mogoče začeti označevanje besed v korpusu. Glavni problem takšnega označevanja je seveda dvoumnost besednih oblik -- tako ima berači štiri možne interpretacije, od katerih bo na določenen mestu v besedilu samo ena pravilna.
Kot je bilo že rečeno, je za avtomatsko določanje pravilne oznake mogoče uporabiti statistične označevalnike, vendar pa ti potrebujejo ročno označen korpus za učenje. Ker tak korpus za slovenski jezik (pa tudi za ostale jezike projekta, razen češkega) ne obstaja, bo v okviru projekta potrebno ročno označiti del korpusa, nato pa v zaporedju več korakov izšolati označevalec, ročno popraviti rezultate in postopek nato ponoviti na razširjeni učni množici. Ker označevalci potrebujejo velike učne množice, ročno pregledovanje pa je izredno zamudno delo, bodo rezultati projekta tu samo pripravljalni. Verjetno bo ročno pregledan samo del korpusa, ker pa je potrebna velikost učne množice odvisna tudi od števila možnih oznak, bo število oblikoslovnih oznak v besedilu zgoščeno glede število slovarskih oznak.
Kot je bilo že rečeno, projekt še teče, vendar je precejšnje število vmesnih rezultatov že dostopno. Ker uporaba zgrajenih virov pokaže na napake in pomanjkljivosti teh virov, bodo rezultati dostopni v dokončni obliki šele ob koncu projekta, vmesni rezultati pa obsegajo zbran, dokumentiran in bibliografsko ter strukturno označen korpus, definirane oblikoslovne tabele in prvo verzijo slovarja. V nadaljevanju projekta je potrebno izdelati še končne verzije teh virov, stavčno paralelizirati vzporedni korpus ter korpus oblikoslovno označiti.
S tem bo izdelanih nekaj osnovnih računalniških virov za slovenski jezik, ki bodo usklajeni z mednarodnimi standardi in priporočili ter s petimi drugimi jeziki projekta. Kljub temu, da so ti viri premajhni za marsikatero aplikacijo, so vendarle pomembni, saj bodo prvi tovrstni široko dostopni viri slovenskega jezika -- rezultati projekta bodo namreč v neprofitne namene dostopni zastonj. Vsaj za našo skupino na IJS pa so verjetno bolj kot izdelava samih virov pomembne izkušnje, ki smo jih pridobili na projektu, saj predstavljajo osnovo, na kateri bi bilo mogoče zgraditi referenčni korpus slovenskega jezika.
Za popularizacijo (rezultatov) projekta smo na IJS postavili WWW stran z naslovom http://nl.ijs.si/ME, ki vsebuje vse osnovne informacije o projektu, primere iz korpusa ter slovarjev, pa tudi vmesne rezultate projekta.