Corpus Encoding Standard
-
Document CES 1. Annex 10. Version 0.9.1 Last Modified 18 June 1996.

Annex 10
Overlapping hierarchies
| Back to section 4.5
| Back to section 5
| CES 1 Table of contents
|
The classical view of a document prepared for use in corpus-based research is
one in which annotation is added incrementally to the original as it is
generated. For example, a document containing type 1 markup might include the
following:
<p>This is the first sentence. This is the second
sentence.</p>
Sentence boundary markup could be inserted directly into this
document, resulting in the following:
<s>This is the first sentence.</s> <s>This is the second
sentence.</s></p>
However, this is not always possible. For example, if the document
contains the following markup:
<p>According to the visiting leader, the economy of the country is
<q>"better than ever. It is in fact in very good
shape."</q></p>
a likely segmentation into sentences would be
<s>According to the visiting leader, the economy of the country is
<q>"better than ever.</s> <s>It is in fact in very good
shape.</s>"</q></p>
However, this is invalid SGML since the <s> and
<q> tags are not properly nested.
This problem of overlapping hierarchies is a common one when applying SGML to
certain complex descriptive situations, because the data model provided by SGML
is that of an ordered labeled tree. When the phenomena to be recognized are
independent of each other, they generally fail to nest regularly in a single
hierarchy, requiring additional representations to be layered on top of SGML's
basic structures. This occurs when there are multiple hierarchies, each to be
applied to the same data, but where there are a well defined set of independent
and hierarchical information types to be represented (as in the example above).
Other common examples are the conflicts between typographic features (e.g.,
highlighting) and linguistic features such as sentence and word boundaries; and
variant annotations (e;g. segmentations), which are generally non-hierarchical.
There are two basic approaches to this problem (with some variations):
- Make one of the hierarchies primary and the other(s) secondary, and break
any elements of the secondary hierarchie(s) at those points where they overlap
a boundary of the primary hierarchy.
- Store the hierarchies separately, and use indirection to connect them with
the data.
To implement the first option for the example above, the markup
would have to be
<s>According to the visiting leader, the economy of the country is
<q>"better than ever.</q></s> <q><s>It is in fact
in very good shape.</s>"</q></p>
This encoding does not correspond, conceptually or typographically,
with the content of the text, in which "better than ever. It is in fact in very
good shape." is clearly regarded as a single quote. In general, it is often the
case that overlapping hierarchies cannot be meaningfully broken. To preserve
the intended relations among elements, additional markup in the form of
cross-references would be needed to link the fragments of "split tags":
<s>According to the visiting leader, the economy of the country is
<q id=q1 type=part next=q2>"better than ever.</q></s> <q
id=q2 type=part prev=q1><s>It is in fact in very good
shape.</s>"</q></p>
The drawback of this approach is that verification of added markup is
very difficult for the secondary hierarchies, since any of the secondary
elements can be interrupted at any time, and any sub-sequence of the possible
contained sub-elements of an element is legal content for that element.
Further, since the continued parts of elements are linked only by IDREFs or
adjacency, standard SGML processing will not detect a wide variety of illegal
secondary markup structures. This means that extra software tools will be
required to verify that such data is correct as well as interpret the more
complex markup in search and retrieval operations.
Typically, the second option, storing the hierarchies separately, is also
implemented with a notion of primary and secondary markup. The primary markup
is that recorded directly with the data in a single document, while secondary
markup is associated with portions of the primary document by indirect
reference. This method uses several SGML documents to represent a single
logical document, but, because of that, can allow many parallel markup patterns
for a base text, even ones added at a later time and not anticipated in the
original tagging scheme. This method, in essence, treats the secondary markup
schemes as annotations to the primary scheme.
For example, assuming the "base" document containing the quotation example
above, the following markup for sentence boundaries would appear in a separate
segmentation annotation document:
Base document:
<p id=p1>According to the visiting leader, the economy of the
country is <q id=q1>"better than ever. It is in fact in very good
shape."</q></p>
Segmentation document:
<s from="ID(p1) STRLOC(1)" to="ID(q1) STRLOC(18)">
<s from="ID(q1) STRLOC(20)" to="ID(q1) STRLOC(52)">
(Note: In this example we use TEI notation involving ID references and
character offsets to designate the target of the link.)
This is conceptually equivalent to inserting the markup for sentence boundaries
as follows:

The separate markup strategy is in essence a finely linked hypertext
format where the links signify a semantic role rather than navigational
options. That is, the links signify the locations where markup contained in a
given annotation document would appear in the document to which it is
linked. As such the annotation information comprises remote markup which
is virtually added to the document to which it is linked. In principle, the two
documents could be merged to form a single document containing all the markup
in each.
Another example where the SGML hierarchical view of documents is not convenient
is for alignment of parallel documents, such as translations, transcription and
recording of speech, etc. The alignment information is non-hierarchical;
instead, it consists of a set of links between arbitrary regions of two or more
documents. These links are the same as the kind of links used in hypertext
systems to associate arbitrary pieces of documents.
For example, assume two parallel documents with regions delimited by
<x> and <y> tags, respectively, which are to be
aligned:
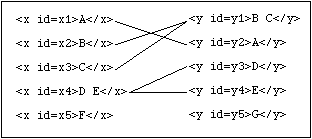
The regions are associated by means of a table indicating the correspondences
(expressed here in TEI HyTime-based pointer notation):
<link targets='x1 y2'>
<ptr id=p1 target='x2 x3'>
<link targets='p1 y1'>
<ptr id=p2 target='y3 y4'>
<link targets='x4 p2'>
<link targets='x5'>
<link targets='y5'>
| Top
| Back
| CES Contents
| CES Annexes
|