The novel ``1984'' by George Orwell is the central component of the
MULTEXT-East corpus: it is the parallel text, where the English original is
to be sentence aligned with the six languages of the project, and
each translation tagged for part-of-speech. Despite the small size of
this parallel corpus (7  100k words), it can nevertheless
constitute a valuable linguistic resource for the MULTEXT-East languages,
especially as the project will also deliver lexica which cover the
word-forms of ``1984''.
100k words), it can nevertheless
constitute a valuable linguistic resource for the MULTEXT-East languages,
especially as the project will also deliver lexica which cover the
word-forms of ``1984''.
It is therefore important that the CES1 structural markup of ``1984'' is similar across the languages. Given that the CES and it's documentation is still evolving, and that for some sites the MULTEXT-East project is their first experience with SGML, the different sites used different markup to describe identical structures. We plan to revise some of the markup of ``1984'' in the second year of the project.
To facilitate this harmonisation, and as an example of the kinds of tags used in the markup, we give the following table, which provides a tag-usage overview of the MULTEXT-East multilingual parallel corpus:
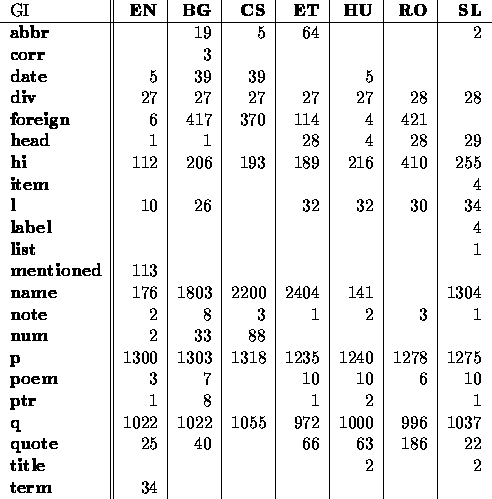
Tagusage in Orwell's ``1984''