COP project 106 MULTEXT-East Newspapers, Bulgarian
Contributors: Institute of Mathematics, Bulgarian Academy of Sciences
The corpus contains about 150 articles (97256 words) from the daily newspapers ``Capital'', ``Continent'', ``Pari'' and ``Standart''.
The corpus was mainly obtained from the publishers of ``Pari'' and ``Standart''. This was done on a ``friendship'' basis --- there was no official agreement between the Institute of Mathematics and the Publishing houses. Due to this, we had not much choice on selecting appropriate articles. Moreover, part of the articles do not contain the name of their author. In such cases we have marked the publisher as an author. The dates when the articles were published were not known for some of the articles, so no information is given in these cases. Actually we did not have half of the electronic texts as published paper.
A small part of the corpus was typed-in (excerpts from the newspapers ``Continent'' and ``Capital''). These texts are marked to the level of sentence (sentence excluded).
The corpus consists of 6 supersections, <div type=supersection>
corresponding to the different sources of articles. Each supersection is identified with id=Newsbg.N , N =1--6.
Each supersection consists further of articles, some of which are grouped into sections (pertaining to a distinct topic, e.g.\ Politics). Each <div> has an id attribute with subsequent numbering.
The <div type=article> and optionally <div type=section>
usually starts off with one or more <head> tags, giving the headline(s).
Pictures accompanying the articles are tagged by <figure>
The attached text and the author are tagged by <caption type=attached>
and <caption type=byline> . <gap> is used to indicate that the figure itself is not there. The place of a figure in the text is given using <ptr> .
If a picture is given in the newspaper alone - not accompanying an article, it is given in <div type=frame> . It may have <head> and <caption>
for the text, attached to the picture.
Small pieces of information are tagged with <div type=brief-news> , <head> is optional for them. Usually such pieces in the newspapers are presented in a group. This is accounted for by the <div type=chronicles> .
The following is an example from the Bulgarian Newspaper corpus; the
characters are, in the original, encoded as SGML ISO Cyrillic entities
(e.g. о); to make the following sample more readable,
they were automatically transliterated into Latin (e.g.
о 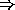 o).
o).
<div type=frame id=Newsbg.2.1.2> <figure> <gap> <caption type=attached> Siediem pozharni koli i diesietki ogniebortsi gasikha v prodhardlzhieniie na chas vchiera pozhar na pokriva na koopieratsiya na <address> <abbr>ul.</abbr> <hi rend=dblq>San Stiefano</hi> <num>17</num> </address> v stolitsata. <q>Dnies bieshie prokliet dien, gasikhmie na tri miesta v <name type=place>Sofiya</name></q>, kazakha pozharnikari. Do khardsniya sliedobied pozharitie v stranata byakha <num>12</num>, informirakha ot <name type=org>Natsionalnata sluzhba za protivopozharna okhrana</name>. </caption> <caption type=byline>Snimka <docAuthor>Vasil MILANOV</docAuthor> </caption> </figure> </div>
The original electronic files were made by the newspaper editors. The provided texts contained usually preliminary versions of the articles and in general no identification information (date, author) This information was supplied by us comparing the text and the published newspaper.
The following is an example from the original digital source; the characters are, in the original, encoded in an 8-bit Cyrillic font --- to make the following sample readable, they were automatically transliterated into Latin.
Siediem pozharni koli i diesietki ogniebortsi gasikha v prodhardlzhieniie na chas vchiera pozhar na pokriva na koopieratsiya na ul. San Stiefano 17 v stolitsata. Dnies bieshie prokliet dien, gasikhmie na tri miesta v Sofiya, kazakha pozharnikari. Do khardsniya sliedobied pozharitie v stranata byakha 12, informirakha ot Natsionalnata sluzhba za protivopozharna okhrana. Snimka Vasil MILANOV
The texts have been first converted to ASCII texts, then spell-checked and all ``strange'' symbols removed. The texts have been marked up to CES1 conformance manually. As the nsmgl editor could not be started, programs have been written to count the tags, to do syntactic validation, clean the text of unnecessary spaces, etc.
However in its most, the markup process was manual.