COP project 106 MULTEXT-East Fiction, Bulgarian
Contributors: Institute of Mathematics, Bulgarian Academy of Sciences
The Bulgarian MULTEXT-East fiction corpus contains the novel ``PASSION or the death of Alice'' by Emilia Dvorianova and and the first four chapters of the novel ``I want, I believe, I can'' by Julia Berberyan.
The first novel was first published by ``OBSIDIAN'', Sofia in 1995, the second - by ``Abagar Holding'', Sofia in 1995. The Bulgarian site obtained the author's / publisher's agreement allowing the use of novels for the purposes of the MULTEXT-East project.
``PASSION or the death of Alice'' was provided in WINWORD format, while ``I want, I believe, I can'' in 'Page maker' format. The texts were converted to ASCII files.
The Bulgarian Fiction corpus contains 98371 words. The first part (``PASSION or the death of Alice'') contains 54100 words approx., the second part - 44200 words approx.
The corpus body consists of 15 <div type=chapter> , the number of each chapter is given in the attribute n of the tag. The chapters from ``I want, I believe, I can''start with a <head> giving the title of the chapter.
The <div type=chapter> elements have the n attribute, giving the chapter number, and the id attribute, whose value has the prefix Fictbg followed by a period, a string, identifying the book, and the chapter number, for example <div type=chapter n=1 id=Fictbg.alice.1.1> .
The text is segmented into paragraphs, with the <head> , <quote> , <opener> , <poem> elements marked-up at the paragraph level.
Sub-paragraph tagging consists of <abbr> , <foreign> , <hi>
<date> , <name> , <l> , <num> and <q> . Direct speech has been marked-up by <q> . ``PASSION or the death of Alice'' is tagged in full at the sub-paragraph level. ``I want, I believe, I can'' is tagged partially.
Rendering information, given as the CES conformant two-letter value of the rend attribute has been included with the appropriated tags and, for mdash and capitalisation, retained in the tag content.
The following is an example from the Bulgarian Fiction corpus; the
characters are, in the original, encoded as SGML ISO Cyrillic entities
(e.g. о); to make the following sample more readable,
they were automatically transliterated into Latin (e.g.
о 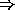 o).
o).
<p> Poslie vlyazokh i mie porhardsi dhardzhd ot shubraka, i pak sie usietikh razshardrdiena, dazhie promhardrmorikh nieshcho nie shardvsiem za kazvanie, shchoto i za tozi shubrak smie sie razpravyali, no za niego gospozhitsata bieshie nieprieklonna i nie sie usmikhvashie, a ustnichkitie ig sie svivakha na dhardgichka: </p> <p> <q rend="PRE mdash"> Da nie si go pipnala, lielsofto <name type=person>Jo</name>!</q> </p>
The versions which were the basis for the encoding, were ASCII files. The text contained a number of misrendered punctuation and spelling mistakes. A spell-checker was used to correct the spelling mistakes. It should be noted that the original electronic texts contained Latin letters used as cyrillic (e.g. latin ``e'' instead of cyrillic ``e'') Their occurrences were discovered by the spell-checker, but we had to substitute latin with cyrillic letters manually. In the following example, the Cyrillic letters have been transliterated back into Latin:
Poslie vlyazokh i mie porhardsi dhardzhd ot shubraka, i pak sie usietikh razshardrdiena, dazhie promhardrmorikh nieshcho nie shardvsiem za kazvanie, shchoto i za tozi shubrak smie sie razpravyali, no za niego gospozhitsata bieshie nieprieklonna i nie sie usmikhvashie, a ustnichkitie ig sie svivakha na dhardgichka: - Da nie si go pipnala, lielsofto Jo!
The version has been marked up to CES1 conformance manually - all tags were inserted manually.